All in One View
Content from APIs & OpenAlex
Last updated on 2024-11-21 | Edit this page
Overview
Questions
- What is an API?
- What is OpenAlex?
- Why do organisations create APIs?
Objectives
- Explain some common uses for APIs (Application Programming Interfaces).
- Conduct a search for a scholarly work using the OpenAlex web interface.
- Navigate the documentation for the OpenAlex API.
- Identify a few key elements for making RESTful API calls via URLs.
What is OpenAlex?
OpenAlex is an open index of over 250 million scholarly works from around the world. It is developed by OurResearch, a nonprofit dedicated to open research. They also developed the Unpaywall browser extension, for example.
Search OpenAlex
Use OpenAlex to retrieve a list of all of the scholarly works from 2023 that were published by authors affiliated with a specific institution. For example, you could look for 2023 publications from University of Minnesota authors.
Tips:
- If you start to type the name of an institution in the search box you will see options to choose items from the database.
- On the search results screen, you can select the big blue “+” button to add or remove filters from your search.
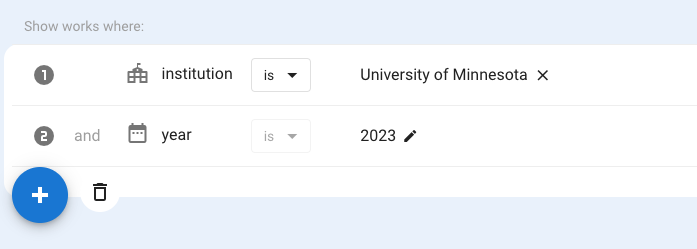
- You can manually construct a search by Institution and Year by starting from the Search Results page and using the filter button to add each element of your query.
You can find the 2023 works by University of Minnesota authors by creating a search where:
- institution “is” University of Minnesota and
- year “is” 2023.
What is an API?
Any user of the OpenAlex web interface can search for scholarly works and display their results in the web browser. OpenAlex also has an API, or Application Programming Interface, which allows for computer programs–rather than a website user–to access contents of the database and download the content in different structured formats. The OpenAlex API provides a way for computer scripts to interact with the OpenAlex servers, and ultimately to access more information than a user of the website could manually access.
Many different websites and publishers provide APIs to their content.
- Newspapers such as the New York Times and the Guardian have APIs that allow developers of other websites or apps to programmatically integrate content from their papers on their sites/apps, for example.
- Government agencies often provide API access to their data: data.europa.eu, for example, provides a central portal for programmatic access to open data from the EU, national, regional, local and geospatial data sources.
- Web and social media companies often offer APIs so that other websites and apps can easily republish or integrate their content: see, for example, the TikTok, Google Maps, Slack, and Facebook/Meta APIs.
One reason publishers create APIs is to allow them to clearly define limits on how their content can be re-used. The New York Times API, for example, does not allow access to the full-text from their articles via the API, and only accepts 500 requests per day and 5 requests per minute (via the FAQ).
API calls
A “call” to an API is the action of programmatically requesting data from an external server, following the API’s defined protocols. That sounds very complex, but in fact many API calls use URLs to query databases, which you can view in your web browser.
The OpenAlex API provides an “institution” search, for example, that
consists of a URL that begins with
https://api.openalex.org/institutions?search= and is
followed by keywords from the name of a university or college. To make
an API call for the University of Tokyo, for example, you could direct
your browser to: https://api.openalex.org/institutions?search=university+of+tokyo.
The API results show a structured response that the web browser doesn’t
display in a user-friendly way, but we’ll explore different ways to
parse, clean, analyze, and visualise that data throughout this
lesson.
Most web APIs that use URLs in this way are known as RESTful (Representational State Transfer) APIs. RESTful APIs rely on constructing URL strings to get the responses you want.
- URLs (Uniform Resource Locators) are strings of characters that point to a data resource online. When we use a web browser, URLs usually point to markup language files such as HTML, which are rendered in your web browser so that they’re easy for you to interact with. When we use a URL to make an API call, however, the response is often in a format that a web browser doesn’t display for human consumption.
- HTTP (Hypertext Transfer Protocol) requests provide for different methods (GET, HEAD, POST, etc.) to interact with online data. We’ll exclusively be making HTTP GET requests to “get” data from the RESTful OpenAlex API. Other HTTP methods, such as DELETE, can be used by developers who have the permissions to modify the database itself via HTTP requests.
OpenAlex API
The OpenAlex technical documentation site provides an overview of the API, including example HTTP Request URLs you can use for making calls to the API. API documentation is an essential tool to help you learn to query the API. API documentation also often spells out for you different requirements for using the API (such as creating a free or paid account) and technical limitations about how often and how much data you can access.
OpenAlex Documentation
Use the OpenAlex API documentation to find out:
- Do you need an account to use the API?
- Is it free to use the API?
- How many API calls can you make per day and per second?
The Rate limits and authentication page notes:
- The OpenAlex API is free and requires no authentication or account to use. You can add your email address to your API calls to get in the “polite pool”, however, which gives you access to faster API response times.
- For free accounts, the rate limits are: 100,000 calls each day and 10 requests per second.
- It’s also possible to subscribe to a Premium plan and raise the API limits. And the docs note: “if you’re an academic researcher we can likely [raise your API limits] for free.”
- OpenAlex is an open index of scholarly works, authors, institutions, and more.
Content from The OpenAlex API
Last updated on 2024-11-22 | Edit this page
Overview
Questions
Objectives
- Import and utilize the requests library to send a GET request to OpenAlex.
- Make an API call for a single work in OpenAlex.
- Navigate the requests response object.
- Use JSON to format and examine data returned from the OpenAlex API.
- Use Python dictionary keys and values to pinpoint specific metadata.
- Use nested key access to navigate nested dictionary data structures.
API call for a scholarly work
Let’s create an API call to obtain metadata related to a single
scholarly work in OpenAlex. To send the GET request to OpenAlex with
Python, we can import the requests library.
Next, let’s structure a URL to send a GET request about a scholarly work to OpenAlex.
OpenAlex provides a series of entities
that we can use to asks for different kinds of data. In this case, we
can use the Works
entity to request data about things like journal articles, books,
datasets, and theses that are indexed by OpenAlex. To access data from a
single work, we can append any DOI (e.g.,
https://doi.org/10.18352/lq.10176) to the base URL for
Works (https://api.openalex.org/works/).
Once we have the URL and DOI ready, we can send it as a parameter of
our GET request using the requests.get() function.
PYTHON
base_url = 'https://api.openalex.org/works/'
doi = 'https://doi.org/10.18352/lq.10176'
# concatenate the URL and DOI strings using the + operator
response = requests.get(base_url + doi)
responseOUTPUT
<Response [200]>The response object will output the HTTP response status code: in our
case, Response [200] means the request succeeded.
We can explore the response in greater depth by calling the
.text() method, which shows the content of the response as
a string.
The output of response.text() is a very long unformatted
string that is pretty difficult to read! Fortunately,
requests includes a .json() method that is
better for working with data that follows the key and value structure
that we see here.
JSON refers to JavaScript Object
Notation, and is a common structure for API responses to follow. In
our case, the .json() method will format the response as a
Python dictionary.
OUTPUT
{'id': 'https://openalex.org/W2560151723',
'doi': 'https://doi.org/10.18352/lq.10176',
'title': 'Library Carpentry: Software Skills Training for Library Professionals',
'display_name': 'Library Carpentry: Software Skills Training for Library Professionals',
'publication_year': 2016,
'publication_date': '2016-11-01',
'ids': {'openalex': 'https://openalex.org/W2560151723',
'doi': 'https://doi.org/10.18352/lq.10176',
'mag': '2560151723'},
'language': 'en',
'primary_location': {'is_oa': True,
'landing_page_url': 'https://doi.org/10.18352/lq.10176',
'pdf_url': 'http://www.liberquarterly.eu/articles/10.18352/lq.10176/galley/10667/download/',
'source': {'id': 'https://openalex.org/S2736366396',
'display_name': 'LIBER Quarterly The Journal of the Association of European Research Libraries',
'issn_l': '2213-056X',
'issn': ['2213-056X', '1435-5205'],
'is_oa': True,
'is_in_doaj': True,
'is_core': True,
...Python dictionaries
This output shows metadata fields stored as ‘keys’ and the data as
‘values’, in the structure of a Python dictionary. Python dictionaries
are key/value pairs that are wrapped in curly brackets–{}–
with the key and value delineated by a colon, and each key/value pair
separated by a comma. The first two key/value pairs in the dictionary
above, for example, are:
{'id': 'https://openalex.org/W2560151723',
'doi': 'https://doi.org/10.18352/lq.10176',The string id is the first key, and the string
https://openalex.org/W2560151723 is its corresponding
value. While these keys and values are both strings, Python dictionaries
can contain other data types as keys and values as well.
2016 in the key/value pair
'publication_year': 2016, for example, is an integer.
While we have a hint that we’re dealing with a dictionary, since the
output of response.json() begins with a curly bracket, we
can check by calling the type() function. First let’s save
the JSON response to a new variable:
OUTPUT
dictTo look at the list of all of the keys in the dictionary, we can call:
OUTPUT
dict_keys(['id', 'doi', 'title', 'display_name', 'publication_year', 'publication_date', 'ids', 'language', 'primary_location', 'type', 'type_crossref', 'indexed_in', 'open_access', 'authorships', 'institution_assertions', 'countries_distinct_count', 'institutions_distinct_count', 'corresponding_author_ids', 'corresponding_institution_ids', 'apc_list', 'apc_paid', 'fwci', 'has_fulltext', 'fulltext_origin', 'cited_by_count', 'citation_normalized_percentile', 'cited_by_percentile_year', 'biblio', 'is_retracted', 'is_paratext', 'primary_topic', 'topics', 'keywords', 'concepts', 'mesh', 'locations_count', 'locations', 'best_oa_location', 'sustainable_development_goals', 'grants', 'datasets', 'versions', 'referenced_works_count', 'referenced_works', 'related_works', 'abstract_inverted_index', 'cited_by_api_url', 'counts_by_year', 'updated_date', 'created_date'])To look at a value associated with a specific key, we can add the key in square brackets (in the same way we refer to a column from a Pandas DataFrame).
OUTPUT
'Library Carpentry: Software Skills Training for Library Professionals'The values of some keys in our json_response are
actually another Python dictionary! We refer to these as nested
dictionaries.
OUTPUT
{'is_oa': True,
'landing_page_url': 'https://doi.org/10.18352/lq.10176',
'pdf_url': 'http://www.liberquarterly.eu/articles/10.18352/lq.10176/galley/10667/download/',
'source': {'id': 'https://openalex.org/S2736366396',
'display_name': 'LIBER Quarterly The Journal of the Association of European Research Libraries',
'issn_l': '2213-056X',
'issn': ['2213-056X', '1435-5205'],
'is_oa': True,
'is_in_doaj': True,
'is_core': True,
'host_organization': 'https://openalex.org/P4310318591',
'host_organization_name': 'Utrecht University Library Open Access Journals (Publishing Services)',
'host_organization_lineage': ['https://openalex.org/P4310318591'],
'host_organization_lineage_names': ['Utrecht University Library Open Access Journals (Publishing Services)'],
'type': 'journal'},
'license': 'cc-by',
'license_id': 'https://openalex.org/licenses/cc-by',
'version': 'publishedVersion',
'is_accepted': True,
'is_published': True}To drill down and take a closer look at these nested dictionary
values, we can keep adding keys using the same square bracket notation.
The title of this publication, ‘LIBER Quarterly The Journal of the
Association of European Research Libraries’, for example, is nested
under two more keys: source and display_name.
To look at that value we can call:
OUTPUT
'LIBER Quarterly The Journal of the Association of European Research Libraries'API call for an institution
- The Institutions entity represents Universities and other organisations to which authors claim affiliations. This provides a way to query the API by institution and retrieve data about the organisation.
Works, Authors, Sources, Institutions, Topics, Publishers, Funders, and Geo. Each entity allows you to construct queries using the entity as a search field, and to explore the entity “object,” which contains data related to each entity type.